Skip to content

TeXNet.ai
![]()
Accurately transcribing mathematical expression into a markup representation gives us hope for bringing new life to old mathematical texts or those for which the source code is unavailable.
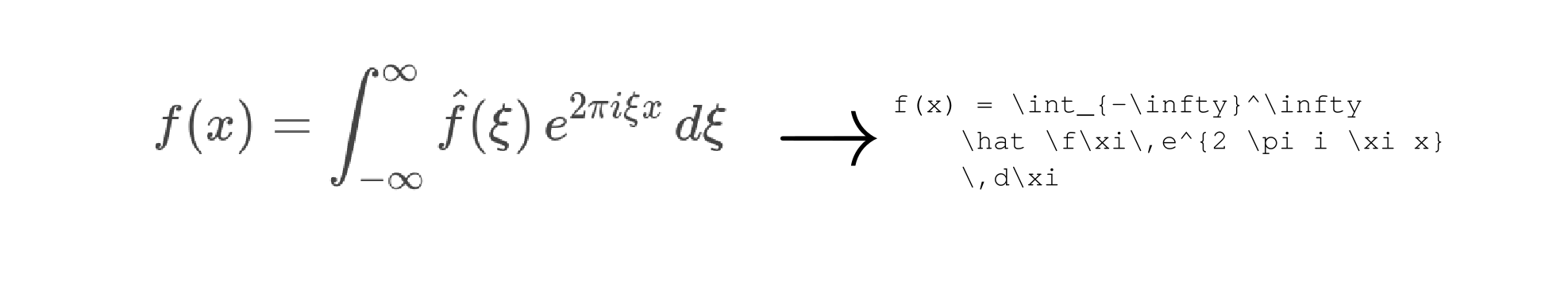
Sumeet Singh's work laid the groundwork for this project. We ported the necessary portions of his model to Python3 and created our own dataset of 170,000 examples generated from mined source code.
Demonstration Video
Preprocessing Pipeline
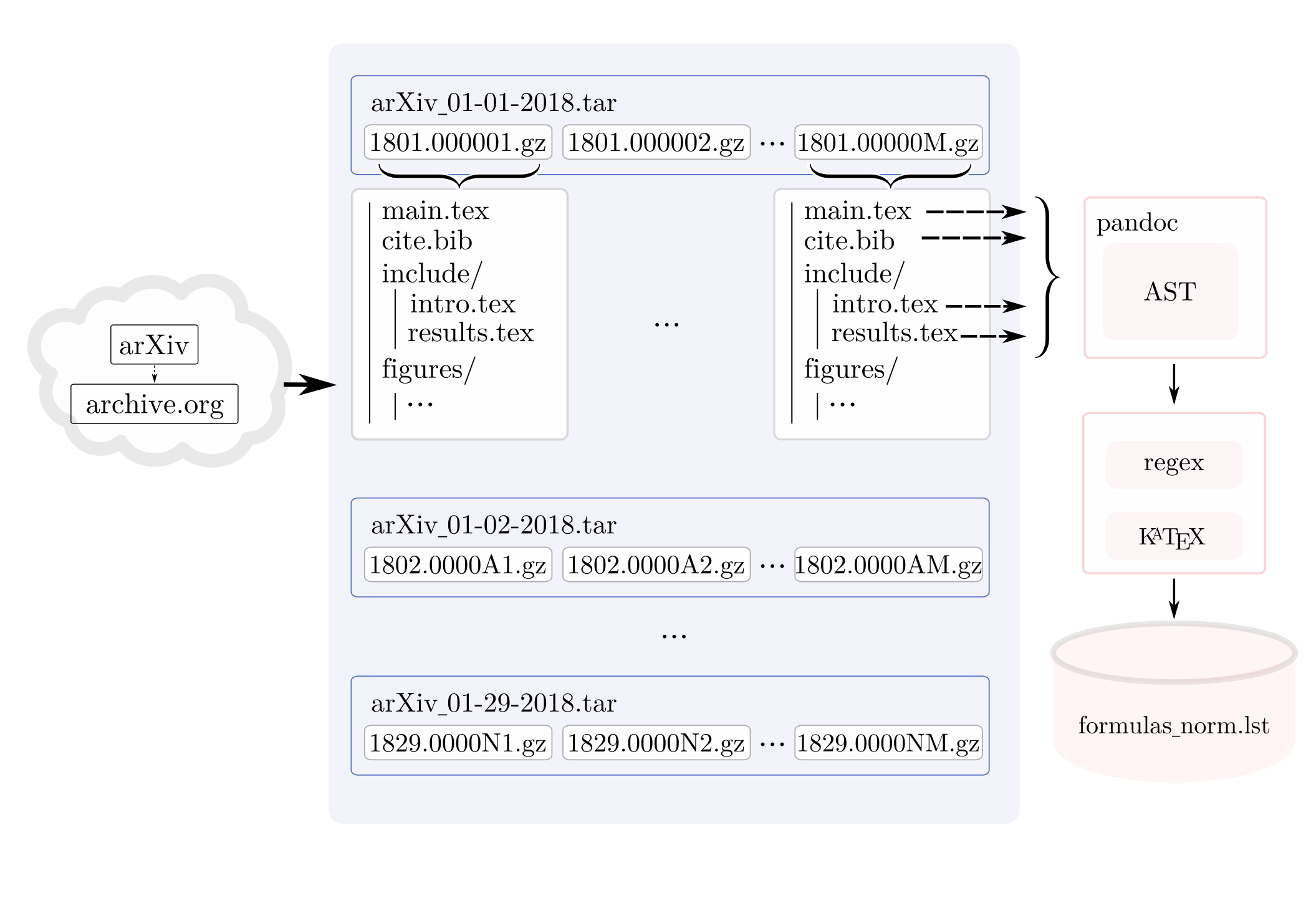
LaTeX is a very dynamic language so increasing the size of our data with
additional examples would be prohibitively expensive. Instead we built a
pipeline using pandoc to expand macros, aggregate, and normalize LaTeX source
code samples from Cornell's Arxiv.
Additional Resources
Sumeet S. Singh's Project Site
Team